测绘地理信息行业学术、技术和资讯。大地测量、卫星导航、无人机/航空/航天摄影测量、自动驾驶、地图、GIS、地图史等等。原创投稿,邮105319275@QQ.com或微:chxszx2018。
↑ 点击上方「中国测绘学会」
可快速关注我们
摘 要:
针对传统信息量模型在滑坡易发性评价中,直接将各评价因子信息量叠加,未考虑评价因子间权重,对易发性分区结果造成不利影响的问题。该文提出随机森林赋权信息量的滑坡灾害易发性评价方法。首先基于参数优化的随机森林模型计算出客观权重;然后将客观权重赋予各评价因子,对各评价因子信息量加权叠加。基于自然间断点法将得到的综合信息量图进行划分;最后以陕西省汉中市为实验区,从滑坡灾害易发性分区图、分区统计灾害点密度及评价模型ROC曲线精度3个方面,将所提方法与传统信息量法进行了对比;实验结果表明所提方法的准确性、可靠性优于传统的信息量法。可以为滑坡灾害风险评估和管理提供依据。
关键词:滑坡易发性;随机森林;信息量;ROC曲线
引言
我国国土面积辽阔,地貌类型、地形条件、复杂多样。山区占国土面积的70%以上,其中孕育了大量地质灾害。根据自然资源部发布的全国地质灾害信息,2019年全国共发生地质灾害6 181起,共造成211人死亡、13人失踪、75人受伤,造成直接经济损失达27.7亿元。地质灾害严重威胁人民群众的生命和财产安全,直接影响经济发展和社会稳定。然而由于地质灾害自身所具有的不确定性和复杂性等特征,使人类在认识上和管理水平上存在一定的局限性,从而缺乏必要的防灾依据。为了有效预防地质灾害,减少地质灾害所造成的损失,需要对地质灾害的预防、发生有较为全面的认识,从而在制定地质灾害防治对策时,能够更加有针对性。为此对地质灾害易发性进行评价就尤为重要了。
目前,国内外学者常用的滑坡灾害易发性评价模型主要包括:经验模型[1-2](层次分析法、模糊逻辑等)、机器学习模型[3-5](人工神经网络、随机森林、支持向量机等)、统计分析模型[6-8](确定性系数法、证据权法、信息量法等)。在滑坡易发性评价中,各类评价因子对滑坡灾害发育所造成的影响十分复杂,很难从理论层次上表达出各评价因子不同子类对滑坡灾害发育过程的促进关系。而针对这一问题信息量模型则表现出了优势。信息量法是从信息理论中引出的一种统计预测方法,该方法通过信息量值来反映不同子类对滑坡灾害发育的促进程度。由于该方法客观高效,在地质灾害易发性评价中应用广泛。文献[9]引入信息量模型对重庆涪陵区进行滑坡灾害易发性评价,取得了较好的评价效果,表明信息量模型作为客观的统计分析模型在区域滑坡灾害易发性评价中具有良好的适用性。但该模型未考虑各评价因子权重,而不同评价因子对滑坡灾害发生的作用程度不同,影响易发性评价效果。近年来,研究者不仅仅注重单一模型的选取,更多的研究者对不同的模型进行对比以及重新组合。文献[10]将信息量模型与逻辑回归模型相结合对汶川县地质灾害进行评价,将信息量计算方法的严密性与逻辑回归评价结果以概率模式显示相结合,使评价结果更具合理性。文献[11]将层次分析法与信息量模型相结合对四川通江县地质灾害危险性进行评价,解决了定性与定量、可靠性与效率之间的矛盾。但层次分析法依靠专家经验对各因素重要性进行打分,具有一定的主观性,对评价结果造成不利影响。
本文基于参数优化的随机森林模型提出了一种客观赋权方法,该方法旨在确定各评价因子权重,降低主观因素对评价因子权重的影响,提高滑坡灾害易发性评价的准确性。研究成果将为有关部门对地质灾害预警和决策提供支持,具有一定的实际应用价值。
研究区概况及数据源
1
研究区概况
汉中市位于祖国西南部,北界秦岭山脉,南界大巴山,总面积27 246 km2。中部是由汉江冲积而形成的汉中平原,属亚热带气候。汉中市位于汉中盆地的中部区域,汉水流域的上游,东经105°30'50"~108°16'45",北纬32°08'54"~33°53'16"之间。汉中地区地跨秦岭褶皱系和扬子准地台两大地质构造单元,地史上频繁的构造运动及强烈的岩浆活动使区域内地质情况复杂。地形从总体上看呈南低北高的特点,市内有平原、丘陵和山地3种地貌。平原区主要分布在海拔500~600 m之间,地势较为平坦,土壤肥沃,占全市面积的34.62%;丘陵地区分布于海拔601~800 m之间,地势起伏较大,约占全市面积的28.1%;秦岭南坡形成的浅山和中山地区是汉中市的主要山地区域,地势较为复杂,其海拔在701~2 038 m之间,约占全市总面积的37.2%。以上复杂的地质地貌条件,共同孕育了汉中市滑坡灾害频发的自然环境。因此,选取汉中市作为本文的研究区。
2
数据源及评价因子选取
汉中市滑坡灾害点数据来源于中国科学院资源环境科学数据中心的“地质灾害点空间分布数据”(?DATAID=290),数据格式为excel和矢量shape文件格式。汉中市地质岩性数据来源于中国科学院资源环境科学数据中心的“中国地质岩性空间分布数据”(?DATAID=307)。数字高程模型(digital elevation model,DEM)数据、居民点数据来自于全国第一次地理国情普查成果数据。道路数据、水系数据是由OpenStreetMap提供的公开数据集。本文以分辨率30m×30m 作为评价栅格单元大小,基于 ArcGIS 将研究区划分为 10 320列、7592 行,共 42979393 个评价栅格单元。
研究区内共有1818个滑坡灾害点,为了保证样本的平衡性,在灾害点1km外随机选取1818个随机点共同构成样本点。在评价因子选取方面,考虑到地形因子是控制斜坡的临空条件,较大程度上决定了滑坡的发育及分布状况。为此提取高程、坡度、坡向,作为地形的反映因子。岩组作为斜坡的基本构成单元,其性质对斜坡稳定性具有绝对的控制作用,因此选取岩组作为评价因子之一。河流对岸堤的冲刷作用、雨水侵蚀、地下水变化,都会导致土壤质地软化从而引起滑坡,故选取年累计降雨量及距河流距离作为反映研究区水文条件的评价因子。研究区内人类工程活动频繁区域多为滑坡灾害频发区,选取距居民点距离,距道路距离作为反映人类工程活动强度的评价因子。
本文结合各评价因子自身特点,采用多种分级标准,对评价因子进行分级。自然间断点法是一种依据数值统计分布规律分级和分类的统计方法, 它能使类与类之间的不同最大化。因此将降雨量、坡度、高程,按照自然间断点法分级。将坡向按方向分级。道路、河流,以500m为步长进行分级。考虑到人类活动的广泛性及复杂性,故距居民点的距离以5km为步长进行分级。针对岩土体的整体性及复杂性,本文将岩组整体划分,根据滑坡灾害点在各岩组分布的点密度,将岩组划分为4类,分别为稳定岩组、偶滑岩组、易滑岩组和极易滑岩组。
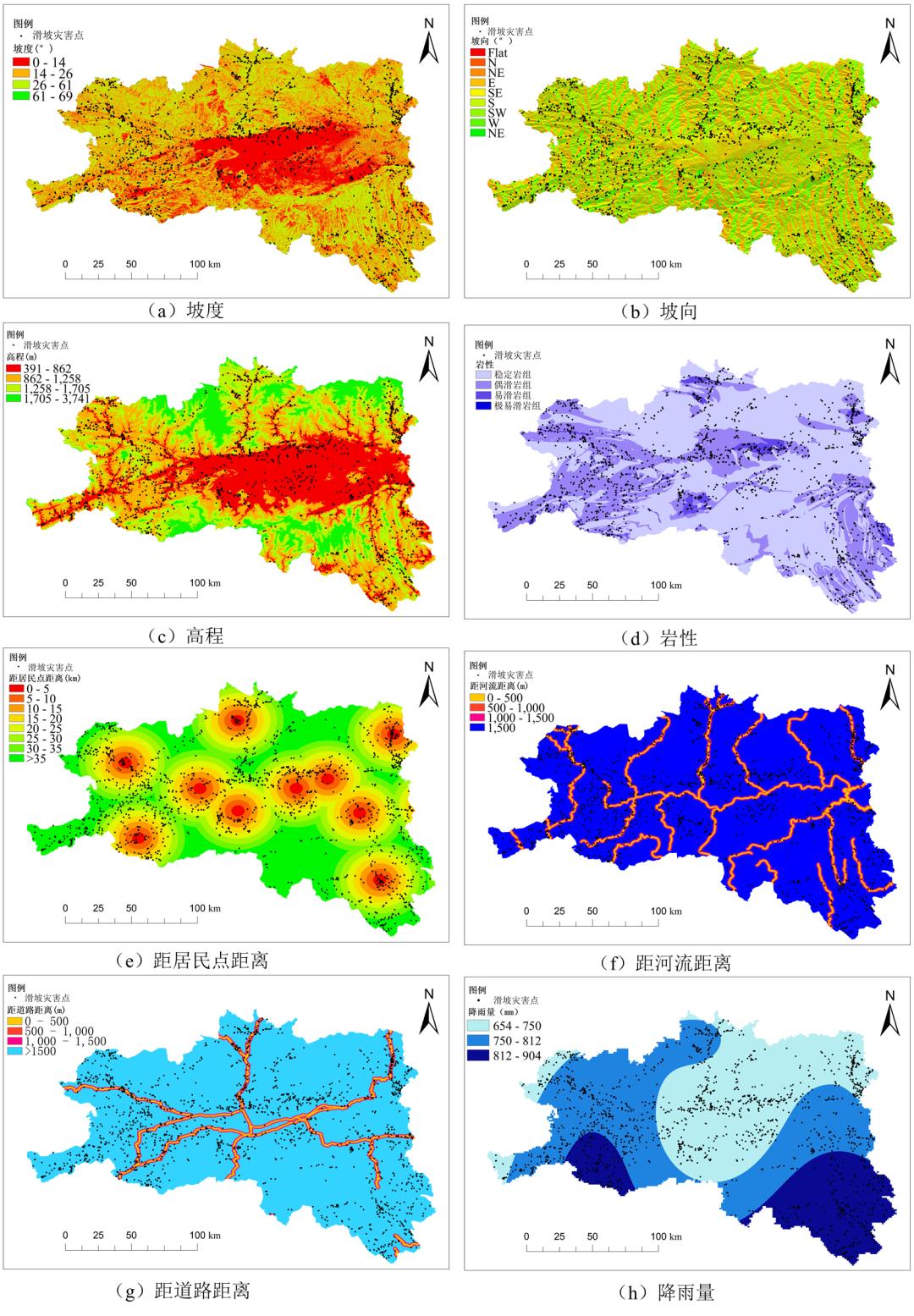
图1 评价因子
研究方法
1
信息量模型
信息量模型通过统计学的方法,计算出各评价因子中不同子类的信息量值,并以此来表示其对灾害发育的促进程度。该方法客观高效,应用广泛。在滑坡灾害易发性评价中,信息量模型以各评价因子所贡献的信息量值大小与综合水平为标准,进行区域滑坡易发性分区,计算各评价因子对滑坡灾害信息量贡献值是该模型的核心[12]。
2
随机森林模型
随机森林是一种组合分类模型,它由多棵决策树 组成。参数集是独立同分布的随机向量,在给定自变量的情况下,最优分类结果由每棵决策树模型投票选出[13]。在随机森林模型中,每棵树的训练样本及节点的分裂属性均为随机选取,在两处随机性共同作用下,一定程度上避免了模型的过拟合,使模型更加稳健。此外,国内外大量的理论和应用研究从不同的角度证明了随机森林模型的准确性,该模型对数据集中的异常值及噪声具有良好的包容度,是目前公认的最好的机器学习模型之一[14-16]。
随机森林特性之一是可以给出滑坡易发性评价因子的相对权重,该相对权重基于基尼指数得出。随机森林分类树中用不纯度度量最佳分割,不纯度通过Gini指数法计算得出[13]。通过计算评价因子
在节点分割时基尼指数的减少值;将森林中所有节点的求和后对所有树取平均,即为评价因子的重要性。以评价因子平均基尼减小值占所有评价因子平均基尼减少值总和的百分比度量评价因子的重要程度。
3
加权线性组合
线性加权组合法其本质是利用线性模型综合评价。其原理简单、易于理解,可与GIS技术紧密结合,因此在本领域内应用广泛。鉴于以上优点本文利用该方法对信息量模型组合赋权。
4
滑坡易发性评价
本文通过信息量模型计算出各评价因子图层信息量值。选取随机森林模型得出各评价因子权重,将各信息量图层基于随机森林客观权重加权线性组合,解决了信息量模型定性与定量之间的矛盾,提高了模型的预测精度,最终达到提高滑坡灾害易发性评价结果准确性、可靠性的目的,总体技术流程如图2。
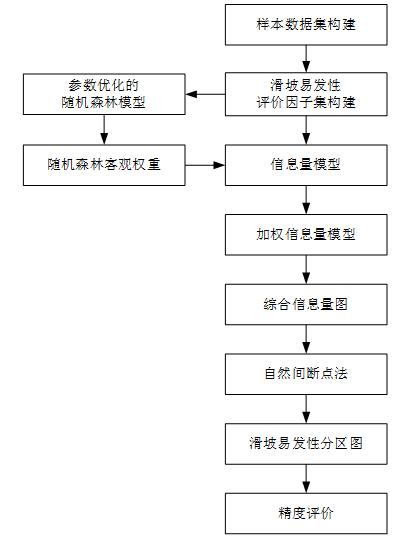
图2 总体技术路线图
1)信息量值计算。将各评价因子分级栅格图与滑坡灾害点分布图叠加,将各个评价因子中各类别的统计结果代入式(1),即可得出各评价因子中各分级分别对滑坡灾害发生所贡献的信息量值(表1)。
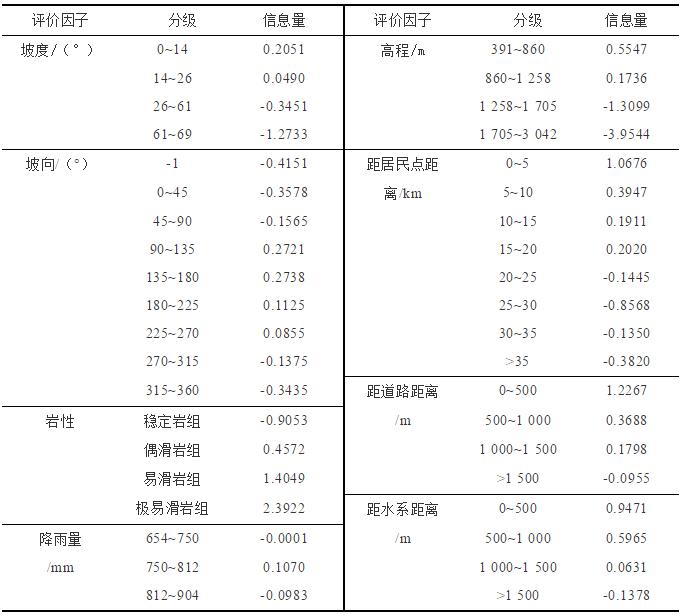
表1 信息量值
2)随机森林模型参数优化。在随机森林分类中,分类树数量n和指定分类树每个节点用于二分数据的自变量个数mtry是随机森林算法中两个重要参数[4]。在R语言中进行循环迭代,由图3可知,当随机特征数为3个时,袋外误差达到最小。此外,在分类树数目为400时,袋外误差趋于稳定,故确定随机森林的决策树数目为400个(图4)。
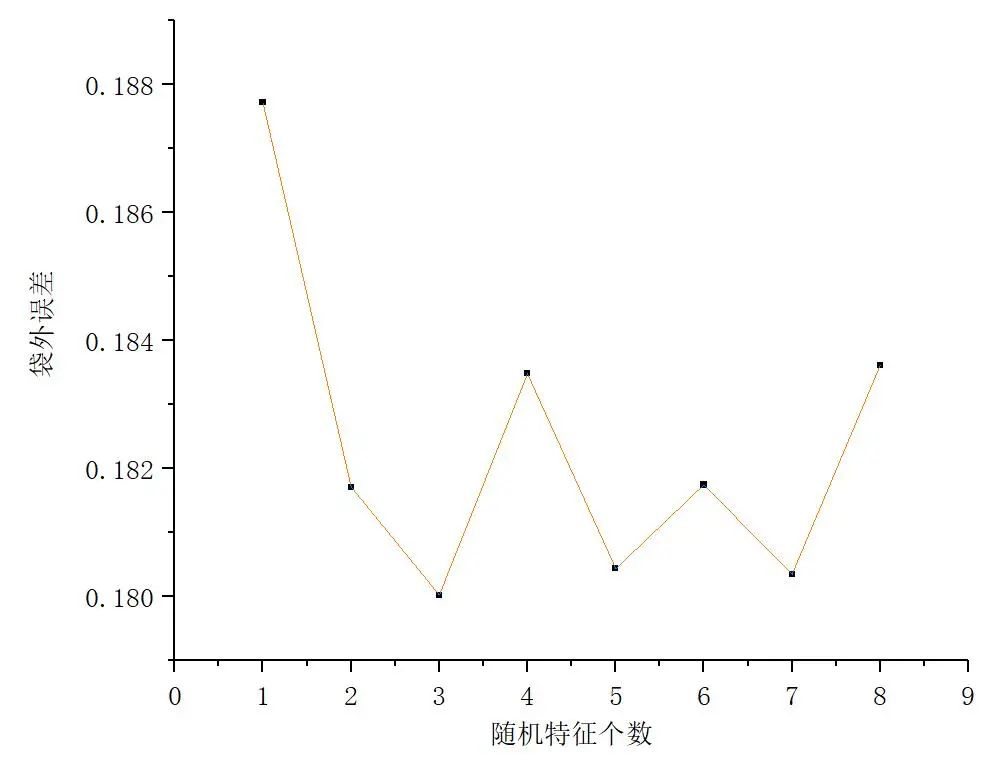
图3不同随机特征数下的袋外误差分布
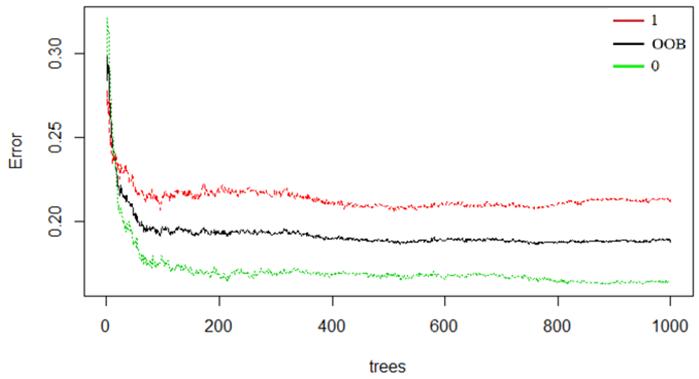
图4模型误差与决策树数量关系
注:图中,1为发生滑坡概率的预测;OOB为袋外误差;0为未发生滑坡的预测。)
3)随机森林权重。选取70%的样本点作为训练数据,30%的样本点作为测试数据。在实验中训练误差率和测试误差率分别为17.89%、17.29%,均小于20%,表明该模型参数设置合理、结果可靠,可进行权重计算。在R语言中利用随机森林模型计算出各评价因子权重,绘制统计图(如图5)。
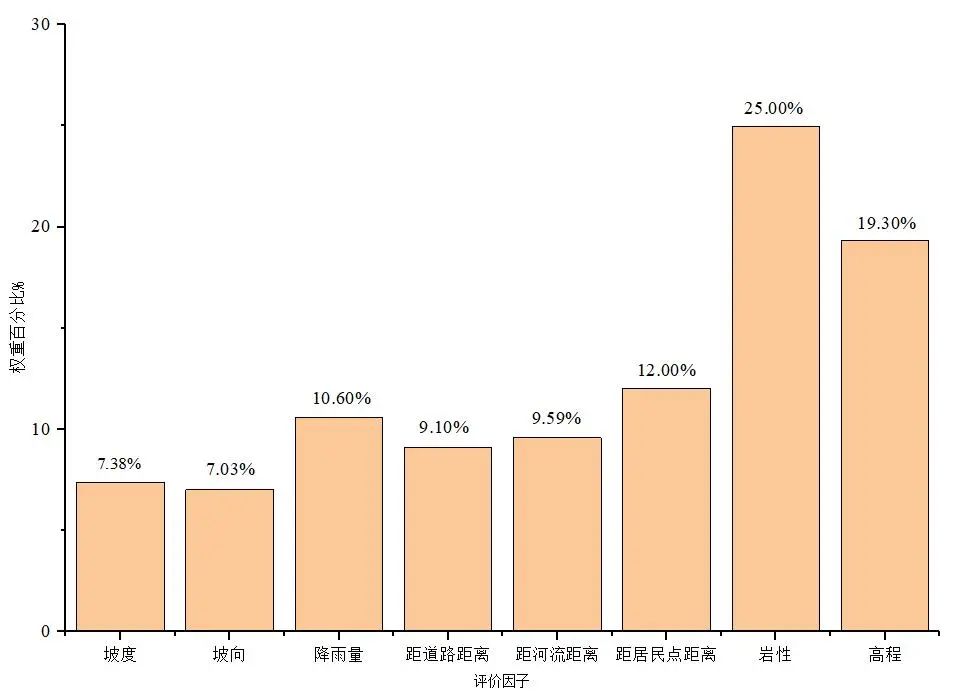
图5 评价因子权重图
4)信息量加权。通过优化随机森林算法计算得到权重值,将权重系数代入式(3),与各评价因子信息量图层线性组合,完成信息量加权。
5)滑坡易发区划分。利用统计学中常用的自然间断点法分别将直接叠加的栅格图和加权叠加的栅格图按信息量值重新分级后,即得到基于信息量模型的滑坡灾害易发性分区图和基于加权信息量模型的滑坡灾害易发性分区图,如图6、图7所示。
6)精度评定。计算ROC(receiver operator characteristic)曲线和曲线下面积(area under curve,AUC)值,分析方法精度。
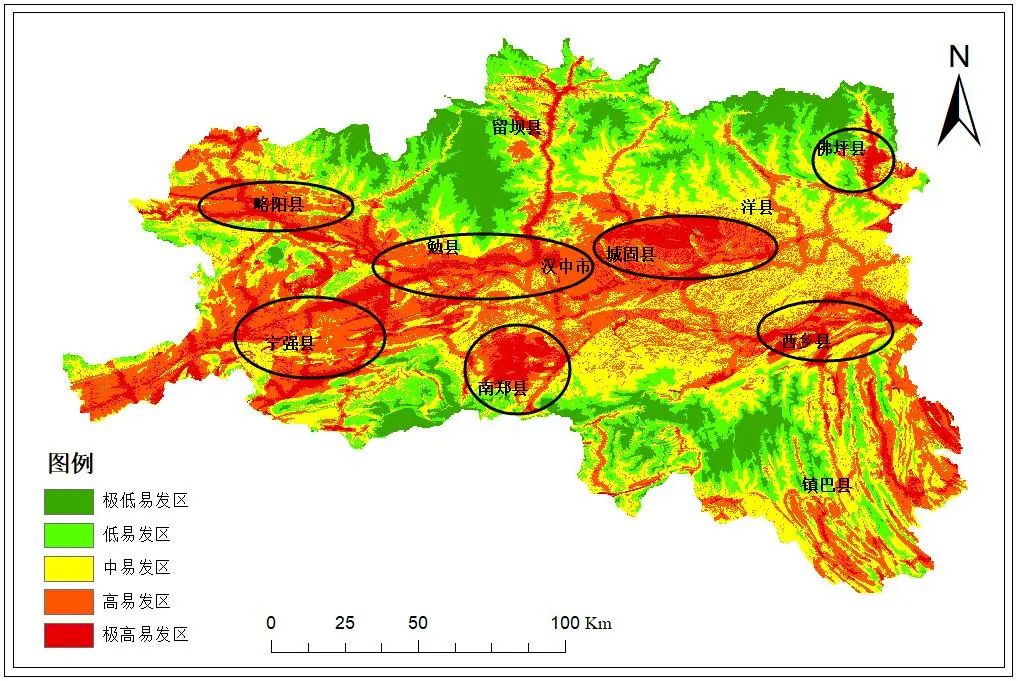
图6基于信息量模型滑坡灾害易发性分区图
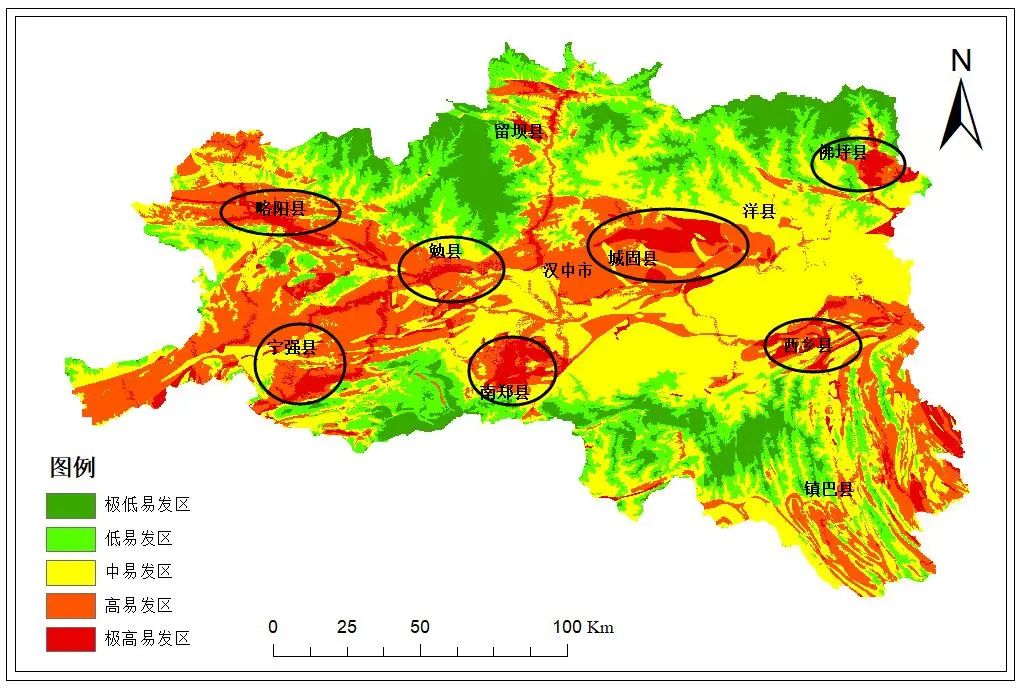
图7 基于加权信息量模型滑坡灾害易发性分区图
结果与分析
为了验证本文方法的正确性和可靠性,利用陕西省汉中市滑坡灾害点数据进行了滑坡易发性评价分析,并从易发性分区图、分区统计灾害点密度及评价模型ROC精度3个方面将本文方法与传统的信息量法进行了对比分析。
1
易发性分区图对比分析
从总体上看,两种模型在易发性评价结果上具有一定的相似性。汉中市滑坡灾害的高发区和极高发区主要集中在汉中市的中部地区并呈条状向东西两个方向延伸。汉中市的中部地区是汉中市的城区附近,随着城市扩张以及人类工程活动的日益频繁,这为滑坡灾害的发生提供了有利的孕灾环境。汉中市西部及东南部等山区亦是滑坡灾害的高发区域,区域内山区沟谷分布密集,地形较为陡峭,在地势的作用下易发生滑坡灾害。在主要道路及河流沿线亦是滑坡灾害高发区域,人类在修建道路时的工程活动及河流对岸堤的冲刷作用为滑坡灾害的发生提供了有利条件。
汉中市东部地区灾害点分布较为稀疏,在加权信息量模型中,多划分为灾害中易发区域,而在单一的信息量模型中仍有大量离散分布的高易发区域,易发区划分不够明确,划分效果较差,在实际应用中缺乏针对性。因此本文划分的易发性等级分区更具合理性、可靠性。
2
易发性分区统计对比分析
将信息量模型和加权信息量模型得出的汉中市滑坡灾害易发性分区图分别与滑坡灾害点叠加,对各易发区内灾害点密度进行统计分析(表2和表3)。灾害点密度统计表显示:在两种模型划分的易发区中随着灾害易发性程度的提高,滑坡灾害点密度亦逐渐提高,在极高易发区内滑坡灾害点密度达到最大。滑坡易发性分区划分结果与滑坡灾害点的分布情况较为吻合,评价效果较好。相较于单一的信息量模型,加权信息量模型在易发性较低的区域灾害点密度与其基本持平,但随着易发性程度的提高,加权信息量模型灾害点密度高于单一的信息量模型,尤其是高易发区和极高易发区,灾害点密度增幅分别达到了0.027个/km2 、0.06个/km2。加权信息量模型灾害点在易发性程度较高的区域中分布更加密集,模型划分结果更加符合灾害点实际分布特征。
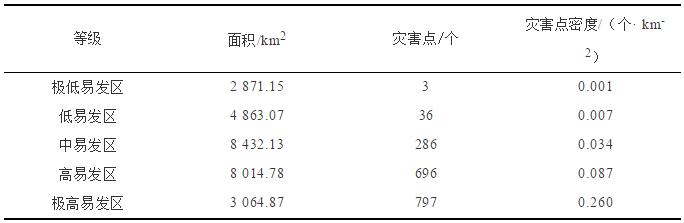
表2 信息量模型滑坡易发性分区统计表
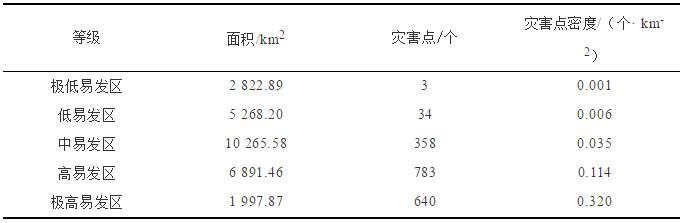
表3 加权信息量模型滑坡灾害易发性分区统计表
3
精度检验分析
ROC 曲线最早源自于统计决策理论,又称为感受性曲线或受试者特性曲线。作为一种结果评价方法,它有不受临界约束的优点,可准确反映所用分析方法特异性和灵敏度之间的关系,具有很好的试验准确性,因而广泛应用于滑坡灾害易发性性评价中[17]。在SPSS中进行分析,ROC曲线下面积(AUC)可以反映和比较模型的评价预测精度(图8)。信息量模型、加权信息量模型AUC值分别为0.784、0.831,即模型的预测精度分别为 78.4%、83.1%。分析结果表明,采用加权信息量模型进行滑坡灾害易发性评价的精度优于信息量模型。
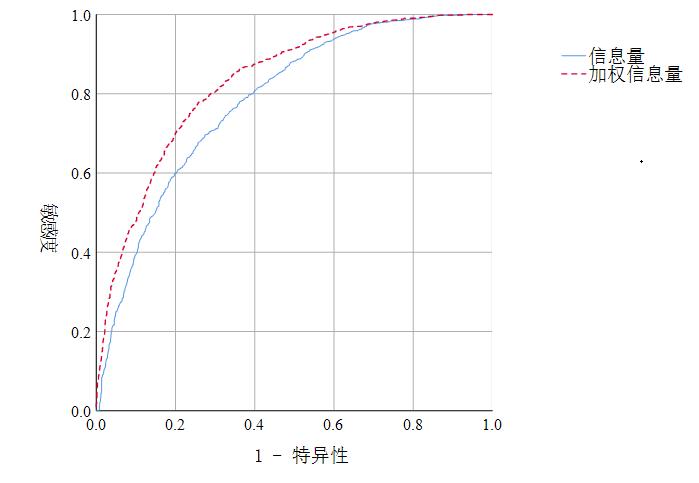
图8ROC曲线
结束语
本文以汉中市1 818个滑坡灾害点为基础,选取坡度、坡向、高程、地层岩性、距河流距离、距道路距离、距居民点距离、累计降雨量8个因子作为滑坡灾害易发性评价因子。分别采用信息量模型、加权信息量模型对汉中市滑坡易发性进行评价和分区,结果显示:两种模型易发区内随着灾害易发性的提高,灾害点密度亦随之提高,在极高易发区灾害点密度达到最大。且相较于单一的信息量模型,加权信息量模型在高易发区内灾害点密度更高。在ROC精度检验中,AUC值分别为0.784和 0.831,两种模型的合理性均符合检验要求。但后者ROC精度更高;结果表明加权信息量模型在滑坡易发性评价结果中与历史滑坡灾害点分布吻合程度更高,滑坡易发区划分效果更好。
原标题:《学术交流丨随机森林赋权信息量的滑坡易发性评价方法研究》



